
Thousands of teams around the world rely on Pivotal Tracker every day to stay focused on their projects. As such, we keep maintenance downtimes to a minimum, but eagle-eyed weekend warriors may have recently noticed status messages about “major” infrastructure updates on two otherwise quiet Saturday mornings.
In fact, those updates were major, and involved moving Tracker to completely new infrastructure—twice. The first move last November was from a proprietary, private hybrid cloud environment at Blue Box to the Pivotal Cloud Foundry PaaS on AWS. Then a few weeks ago we did it all over again, this time moving from AWS to the Google Cloud Platform.
Wondering why we did this, and how we managed to move a large-scale, high-traffic SaaS application multiple times with barely anyone noticing? Keep reading!
Tracker’s been around for over a decade now, starting as an internal tool back in the early days of Pivotal Labs. It was one of the first Rails apps we built, with a fairly typical monolithic web app architecture backed by a single MySQL database.
![]()
Its hosting journey began with a server in a closet designed for mops and brooms. After a few too many incidents of janitors accidentally unplugging the extension cord at night, we finally moved it to a more proper hosting environment: a VPS at rimuhosting.
Then came the growth of Pivotal Labs, and Tracker adoption in parallel, so we needed to get more serious with our production hosting environment. Tracker joined many other Rails apps at Engine Yard, before moving a few years later to Blue Box to take advantage of their Rails-specific managed hosting services.
Tracker’s infrastructure evolved over the five or so years that it was hosted at Blue Box. By the end of our time there, our production stack was made up of the Rails app, workers, Solr, Memcached, Redis instances, and a few other pieces. This all ran on VPSs on a proprietary virtualization layer installed on our own dedicated servers. We relied on two MySQL databases on bare metal: a 250GB operational DB and a 6TB historical snapshot DB.
As a single-page application with real-time updates that stays open on the desktop throughout the day, the Tracker back end gets a lot of traffic. Every week, around 200K new stories are created, 350K new comments are posted, and 2.5M project changes are made.
At peak traffic, Tracker sees around 50K requests per minute, which results in roughly 12K requests per minute (rpm) to the Rails app and 200K rpm to the primary database. Our hosting infrastructure must be able to handle all this load reliably, or thousands of customer projects across the world would grind to a halt.
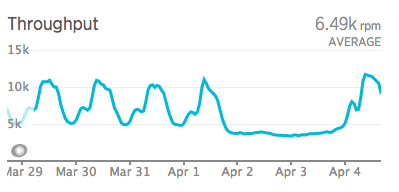
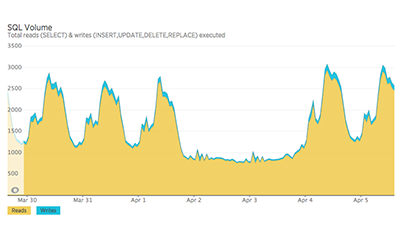
The environment at Blue Box handled this traffic well, in no small part due to the powerful bare metal database servers with 128GB of RAM.
But there were some challenges. Relying on dedicated hardware meant that our resources were fixed, and any increase or decrease involved significant time and effort—to request a server, wait for it to be ordered and provisioned, etc. Our deploy tooling and process were complicated. Upgrades and security patches were major projects.
We toyed with the idea of moving to a more modern, public, cloud-based environment, but the sheer magnitude of such a migration project was just too daunting, so we kept carrying on…until we got an eviction notice. Blue Box was acquired the year before and announced plans to shut down their managed hosting service.
We had six months to find a new home.
The punchline here has already been spoiled, because Tracker obviously kept working—we ended up moving Tracker to a new environment on AWS with about a month to spare.
The actual cutover took around three hours, which included testing the new environment and taking a short lunch break, before flipping the routing switch and removing the “down for maintenance” page. After ensuring that the new environment and database replication were running (i.e., keeping DB in old and new environments in sync), these are the steps we took:
Just like landing a plane, the actual touchdown is relatively easy if you follow the comprehensive landing checklist and prepare the approach properly. We did a lot of up-front work to make sure our touchdown went smoothly!

The first phase of the project was to decide where to move to. We knew we didn’t want to invest in yet another proprietary hybrid hosting environment. The future (actually the present, at this point) is the public cloud, and we had the advantage of being part of Pivotal, the company that makes Pivotal Cloud Foundry (PCF)—a great platform for deploying and managing apps on the cloud.
We decided to move to a PCF instance on AWS, since AWS was the most mature public cloud, and our team already had some familiarity with it. But there was quite a bit of panic when we realized what it would take to re-architect a 10-year-old, high-strung, monolithic Rails app to be able to run on a real cloud environment.
Preparing for the migration took us around 18 “pair months”—we pair program, so always count in developer pairs. The project involved
The new production environment was deployed to a dedicated PCF foundation in the AWS West region, utilizing approximately 80 app instances, along with a number of supporting data and other services including RDS, Aurora, and SolrCloud.
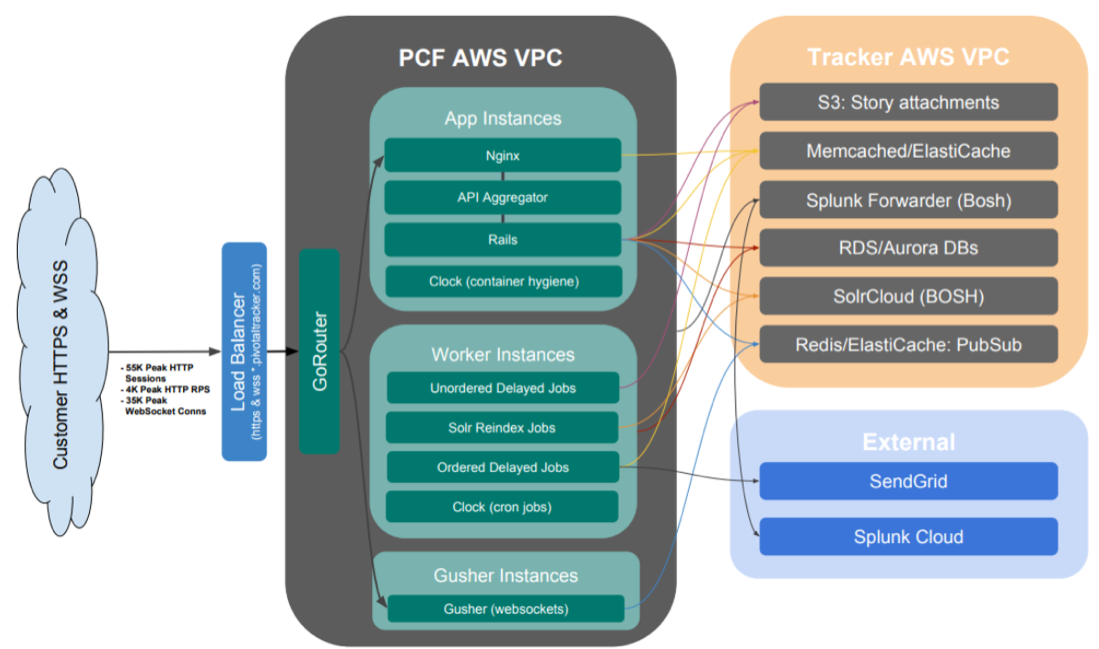
Moving from mostly bare-metal hardware to a fully virtual environment with more layers, we expected some performance tradeoffs, but we actually ended up with about the same or slightly better request times. And with PCF, it’s easy to experiment with resource sizing/scaling to find the best cost vs. performance balance for your app.
You might wonder why we chose to deploy on a PaaS instead of reducing layers and deploying directly to EC2, or using raw docker images. Well, let us count the ways we’ve benefited from running Tracker on Pivotal Cloud Foundry:
As it turns out, that last benefit proved to be quite handy.
The public cloud wars have really heated up this year, with both Microsoft and Google making a big push for IaaS dominance. For us, the Google Cloud Platform started to get interesting late last year for a number of reasons, including the global fibre network, significantly lower pricing compared to AWS (without requiring the use of reserved instances), and Google’s recently announced Customer Reliability Engineering program.
The last thing anyone wants to talk about right after a major infrastructure migration is yet another infrastructure migration! That is, unless you’re running your app on PCF, which frees you from caring too much about the the underlying cloud infrastructure.
So we dove right in.
This time around, the migration was much less work—less than half the original engineering time. We worked closely with Pivotal’s Cloud Ops team, who focused on spinning up PCF on GCP, while the Tracker team handled data export/transfer/import, DB replication, and learning and setting up the GCP-specific services, including Google’s Cloud SQL product.
Thanks to PCF IaaS isolation, there was no need to make any changes to our app, and all of our existing deploy mechanisms Just Worked™.
The cutover to GCP happened on a Saturday morning in late July, and like the first time around, it was completely uneventful. It took less than an hour for the actual cutover, an hour or two for testing the new environment, and then everyone went back home to enjoy the afternoon (while keeping an eye out for for any unexpected issues).
The outcome looks great so far. Tracker and PCF have been rock solid in the new GCP environment, latency outside of the US has been significantly reduced, and our monthly IaaS bill is significantly lower, which makes the finance team very happy.
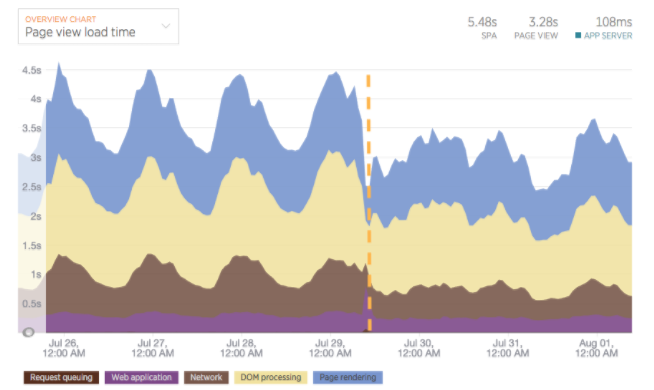
Stay tuned for deeper dives on various aspects of the migration, how we’ve automated our CI/CD and acceptance process with PCF, and more. We’ll also be talking about our journey at SpringOne Platform in December, so come and join the conversation!
Category: News